How to download an entire website with a single command ?

wget is a powerful command-line utility for downloading files from the web. It supports various protocols such as HTTP, HTTPS, FTP, and FTPS.
For Windows: https://gnuwin32.sourceforge.net/packages/wget.htm
For Linux: sudo apt-get install wget It will be available inbuilt mostly.
Get a Free wget cookbook here
Download an entire website
wget --recursive --no-clobber --page-requisites --html-extension --convert-links --domains example.com --no-parent https://example.com
--recursive: Enables recursive retrieval, meaningwgetwill download not only the specified URL but also follow and download links within that page, continuing recursively.--no-clobber: This option preventswgetfrom overwriting existing files. If a file with the same name already exists in the local directory,wgetwill not download it again.--page-requisites: Downloads all the elements needed to properly display the page offline. This includes inline images, stylesheets, and other resources referenced by the HTML.--html-extension: Appends the.htmlextension to HTML files downloaded. This is useful when saving a complete website for offline browsing, as it helps maintain proper file extensions.--convert-links: After downloading, converts the links in the downloaded documents to point to the local files, enabling offline browsing. This is important when you want to view the downloaded content without an internet connection.--domainsexample.com: Restricts the download to files under the specified domain (example.com). This ensures thatwgetdoesn't follow links to external domains, focusing only on the specified domain.--no-parent: Preventswgetfrom ascending to the parent directory while recursively downloading. It ensures that only content within the specified URL and its subdirectories is downloaded.https://example.com: The URL from whichwgetstarts the recursive download.
Example:
wget --recursive --no-clobber --page-requisites --html-extension --convert-links --domains example.com --no-parent https://example.com
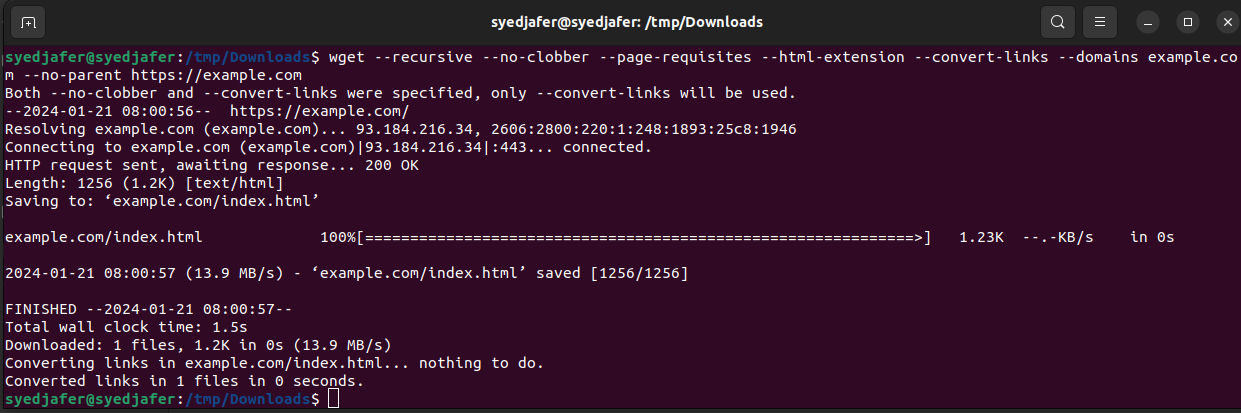
For mirroring the entire website
wget --mirror --convert-links --adjust-extension --page-requisites --no-parent https://example.com

In both the scenarios it will get downloaded in to a folder (named as the domain name)
Let's see what is inside the folder,

On hosting it locally (here i am using python http server)
python -m http.server

While navigating to the url, we can see the entire website is been downloaded/mirrored.